1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
|
import requests,sys,re
import urllib.request
class Bookspider(object):
"""爬取全书网指定书籍并下载到本地"""
def __init__(self):
super(Bookspider, self).__init__()
self.request = requests.session()
self.headers = {
'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
def book_search(self,name):
print('[*]搜索中...')
self.url = 'http://www.quanshuwang.com/modules/article/search.php?searchkey='+urllib.request.quote(name.encode('gb2312'))+'&searchtype=articlename&searchbuttom.x=88&searchbuttom.y=22'
search_data = self.request.get(self.url,headers=self.headers,allow_redirects=False)
try:
self.location = search_data.headers['location']
self.location = self.location.split()
except KeyError as e:
response = search_data.content.decode('gbk')
self.location = re.findall(r'<li><a target="_blank" href="(.*?)".*?title="(.*?)".*>(.*?)</a><em class=.*?>(.*?)<a href=',response)
return self.location
def book_info(self):
res = requests.get(self.location,headers=self.headers).content.decode('gbk')
self.bookname = re.findall(r'<meta property="og:title" content="(.*?)"/>',res)[0]
self.author = re.findall(r'<meta property="og:novel:author" content="(.*?)"/>',res)[0]
self.description = re.findall(r'<meta property="og:description" content="(.*?)"/>',res,re.S)[0].replace(' ','').replace('<br />','').replace(' ','')
self.booklink = re.findall(r'class="leftso png_bg"><a href="(.*?)"',res)[0]
response = requests.get(self.booklink,headers=self.headers).content.decode('gbk')
self.contents = re.findall(r'<li><a href="(.*?)" title="(.*?)">.*?</a></li>',response)
self.len = len(self.contents)
def save(self):
i = 0
with open('%s.txt'%self.bookname,'w',encoding='utf-8',errors='ignore') as text_save:
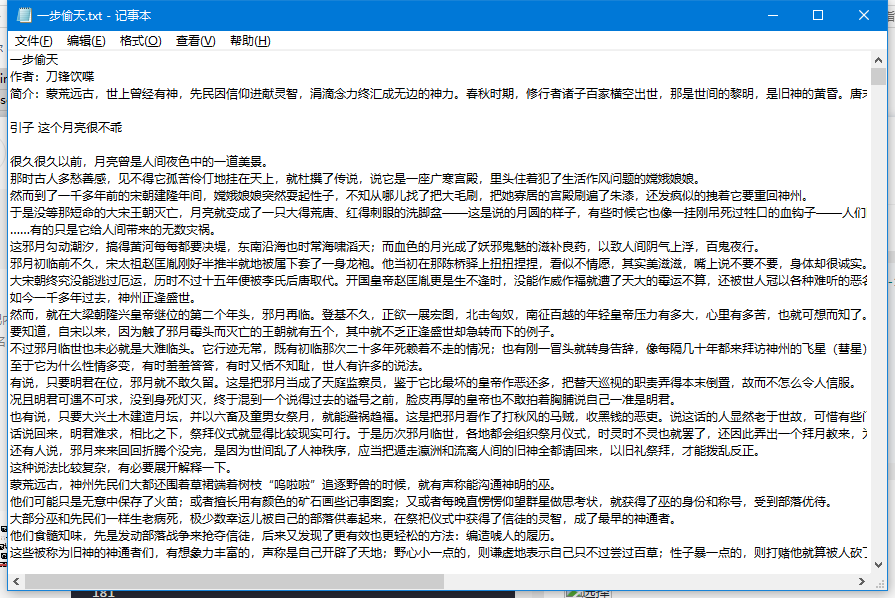
text_save.write(self.bookname+'\n作者:'+self.author)
text_save.write('\n简介:'+self.description)
text_save.write('\n')
for num in self.contents:
text_r = requests.get(num[0],headers=self.headers)
text_c = text_r.content
text = text_c.decode('gbk')
title = num[1].replace(re.findall(r',共\d*字',num[1])[0],'')
try:
text = re.findall(r'</script> (.*?)<script type="text/javascript">',text,re.S)[0]
except IndexError as e:
print('【**】%s下载失败'%title)
text = text.replace(' ','')
text = text.replace('<br />','')
text = text.replace('\r\n\r\n','\r\n')
text_save.write('\n')
text_save.write(title)
text_save.write('\n\n')
text_save.write(text)
text_save.write('\n')
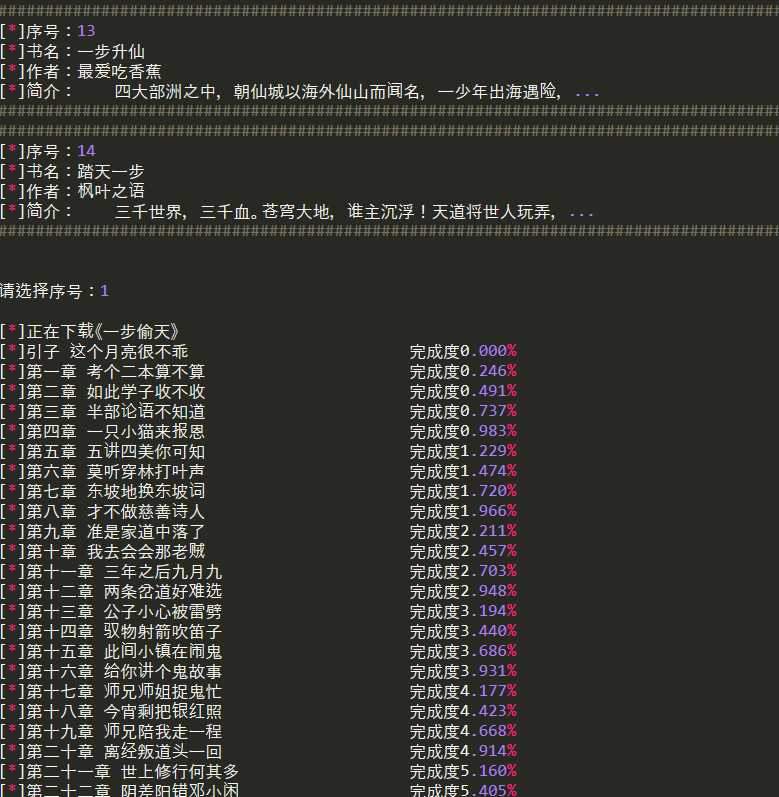
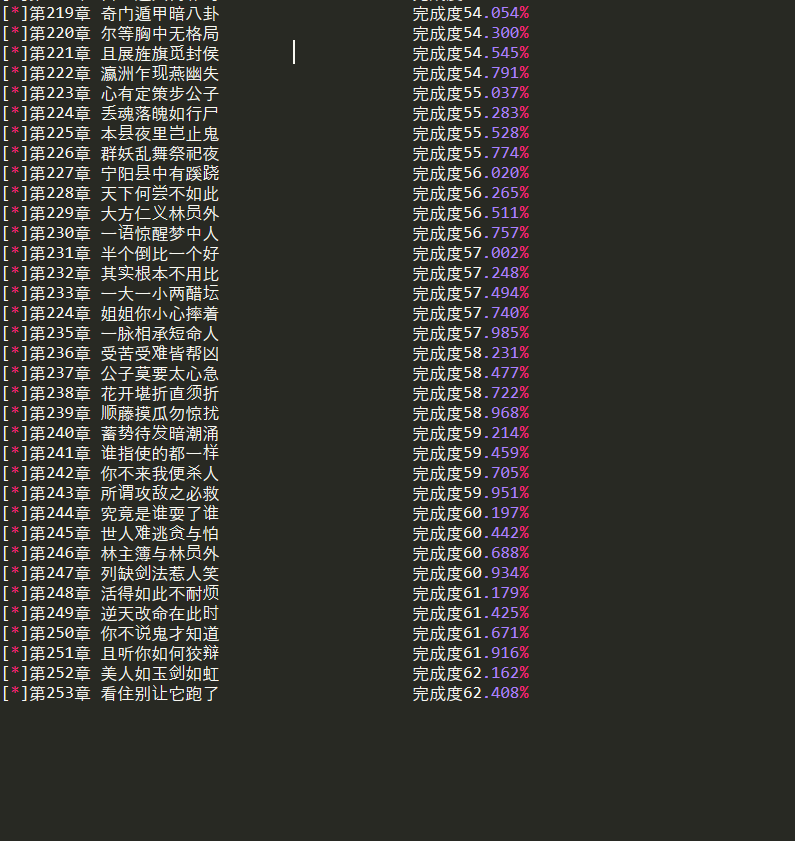
print('[*]%-30s\t完成度%.3f%%'%(title,(i+1) * 100 / self.len))
i += 1
text_save.write('\n===全书完===\n==by苏乞儿==\n')
def get_item(self):
item = len(self.location)
return item
def set_location(self,location):
self.location = location
def get_bookname(self):
return self.bookname
def get_author(self):
return self.author
def get_chapter(self):
return self.len
def get_description(self):
return self.description
if __name__ == '__main__':
book = Bookspider()
name = input('[*]请输入书名:')
locations = book.book_search(name)
item_sum = book.get_item()
if item_sum == 1:
book.set_location(locations[0])
book.book_info()
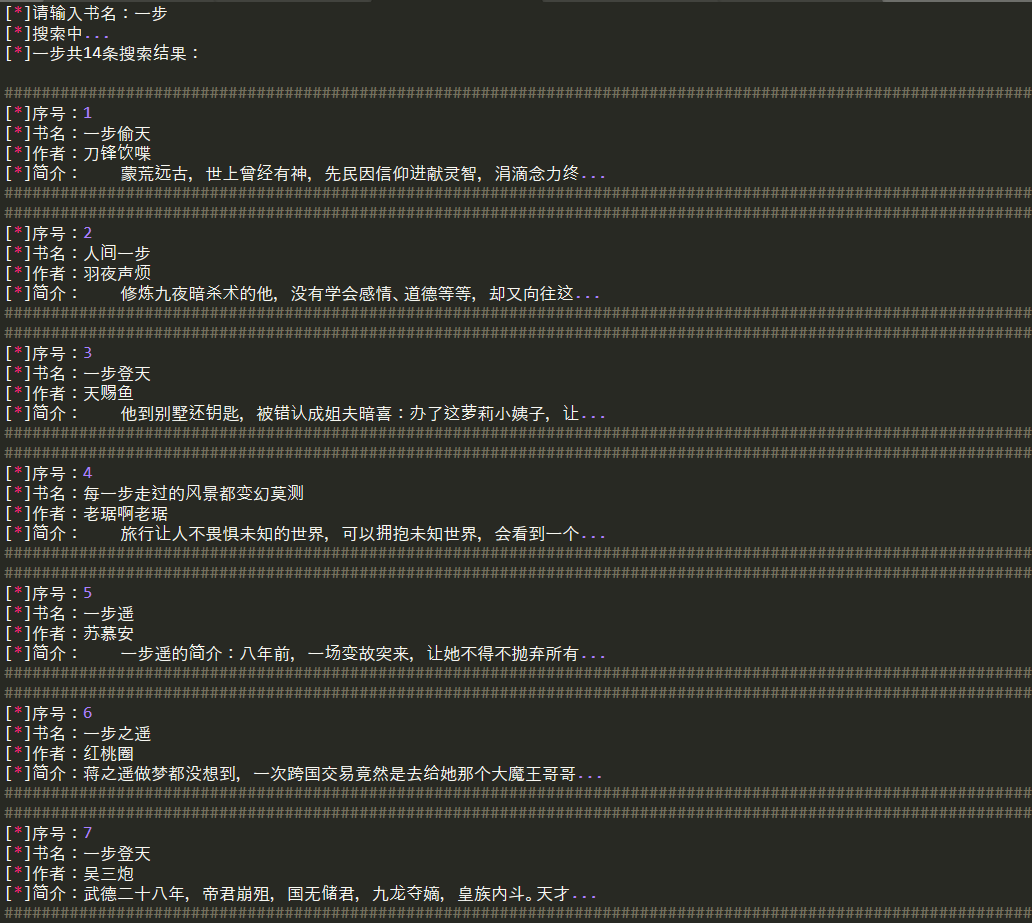
print('[*]%s共%d条搜索结果:\n'%(name,item_sum))
print('#'*150)
print('[*]书名:%s'%book.get_bookname())
print('[*]作者:%s'%book.get_author())
print('[*]简介:%s'%book.get_description())
print('#'*150)
choose1 = input('[*]是否继续下载?(y/n)')
if choose1 == 'y' or choose1 == 'Y':
print('\n[*]正在下载《%s》'%book.get_bookname())
book.save()
else:
print('\n[*]感谢使用!')
sys.exit(1)
else:
j = 0
print('[*]%s共%d条搜索结果:\n'%(name,item_sum))
for item in locations:
print('#'*150)
print('[*]序号:%d'%(j+1))
print('[*]书名:%s'%item[1])
print('[*]作者:%s'%item[2])
print('[*]简介:%s'%item[3])
print('#'*150)
j +=1
choose2 = int(input('\n\n请选择序号:'))
if choose2 >= 1 and choose2 <= item_sum:
print('\n[*]正在下载《%s》'%locations[choose2-1][1])
book.set_location(locations[choose2-1][0])
book.book_info()
book.save()
else:
print('\n[*]感谢使用!')
sys.exit(1)
print('\n[*]下载成功!')
|