1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
|
import urllib.request
import requests,re
import itchat
from itchat.content import *
class BookSpyder(object):
"""爬取指定小说-server版"""
def __init__(self, book_name,book_author):
super(BookSpyder, self).__init__()
self.book_author = book_author
self.headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
self.url = 'http://www.quanshuwang.com/modules/article/search.php?searchkey='+urllib.request.quote(book_name.encode('gb2312'))+'&searchtype=articlename&searchbuttom.x=88&searchbuttom.y=22'
search_data = requests.get(self.url,headers=self.headers,allow_redirects=False)
try:
self.location = search_data.headers['location'].split()
self.location2res(self.location[0])
except KeyError:
self.location = re.findall(r'<li><a target="_blank" href="(.*?)".*?title="(.*?)".*>(.*?)</a><em class=.*?>(.*?)<a href=',search_data.content.decode('gbk'))
for http in self.location:
flag = self.location2res(http[0])
if flag == 1:
break
self.booklink = re.findall(r'class="leftso png_bg"><a href="(.*?)"',self.res)[0]
self.book_name = re.findall(r'<meta property="og:title" content="(.*?)"/>',self.res)[0]
response = requests.get(self.booklink,headers=self.headers).content.decode('gbk')
self.contents = re.findall(r'<li><a href="(.*?)" title="(.*?)">.*?</a></li>',response)
self.len = len(self.contents)
def location2res(self,location):
flag = -1
self.res = requests.get(location,headers=self.headers).content.decode('gbk')
author = re.findall(r'<meta property="og:novel:author" content="(.*?)"',self.res)[0]
if self.book_author == author:
flag = 1
try:
self.description = re.findall(r'介绍: (.*?)</div>',self.res,re.S)[0].replace(' ','').replace('<br />','')
except IndexError:
pass
return flag
def save(self):
i = 0
with open('./book/suqir.txt','w',encoding='utf-8',errors='ignore') as text_save:
text_save.write(self.book_name+'\n作者:'+self.book_author)
if 'self.description' in dir():
text_save.write('\n简介:'+self.description)
text_save.write('\n')
for num in self.contents:
text_r = requests.get(num[0],headers=self.headers)
text_c = text_r.content
text = text_c.decode('gb18030')
title = num[1].replace(re.findall(r',共\d*字',num[1])[0],'')
try:
text = re.findall(r'</script> (.*?)<script type="text/javascript">',text,re.S)[0]
text = text.replace(' ','')
text = text.replace('<br />','')
text = text.replace('\r\n\r\n','\r\n')
text_save.write('\n')
text_save.write(title)
text_save.write('\n\n')
text_save.write(text)
text_save.write('\n')
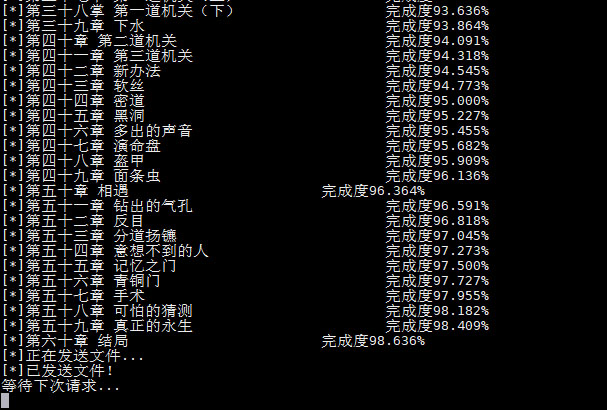
print('[*]%-30s\t完成度%.3f%%'%(title,(i+1) * 100 / self.len))
i += 1
except IndexError as e:
print('【*】%s下载失败'%title)
text_save.write('\n===全书完===\n==by苏乞儿==\n')
def get_bookname(self):
return self.book_name
def get_bookauthor(self):
return self.book_author
def get_des(self):
try:
return self.description
except AttributeError:
return '无简介'
def get_centents(self):
return self.len
def get_booklink(self):
return self.booklink
def getUserName():
itchat.auto_login(hotReload=True,enableCmdQR=2)
onlyUser = itchat.search_friends(name='杰帅')
return onlyUser[0]['UserName']
@itchat.msg_register([TEXT],isFriendChat=True)
def text_reply(msg):
global userName
if msg['FromUserName'] == userName:
try:
bookName,bookAuthor = msg['Text'].split('suqir')
book = BookSpyder(bookName,bookAuthor)
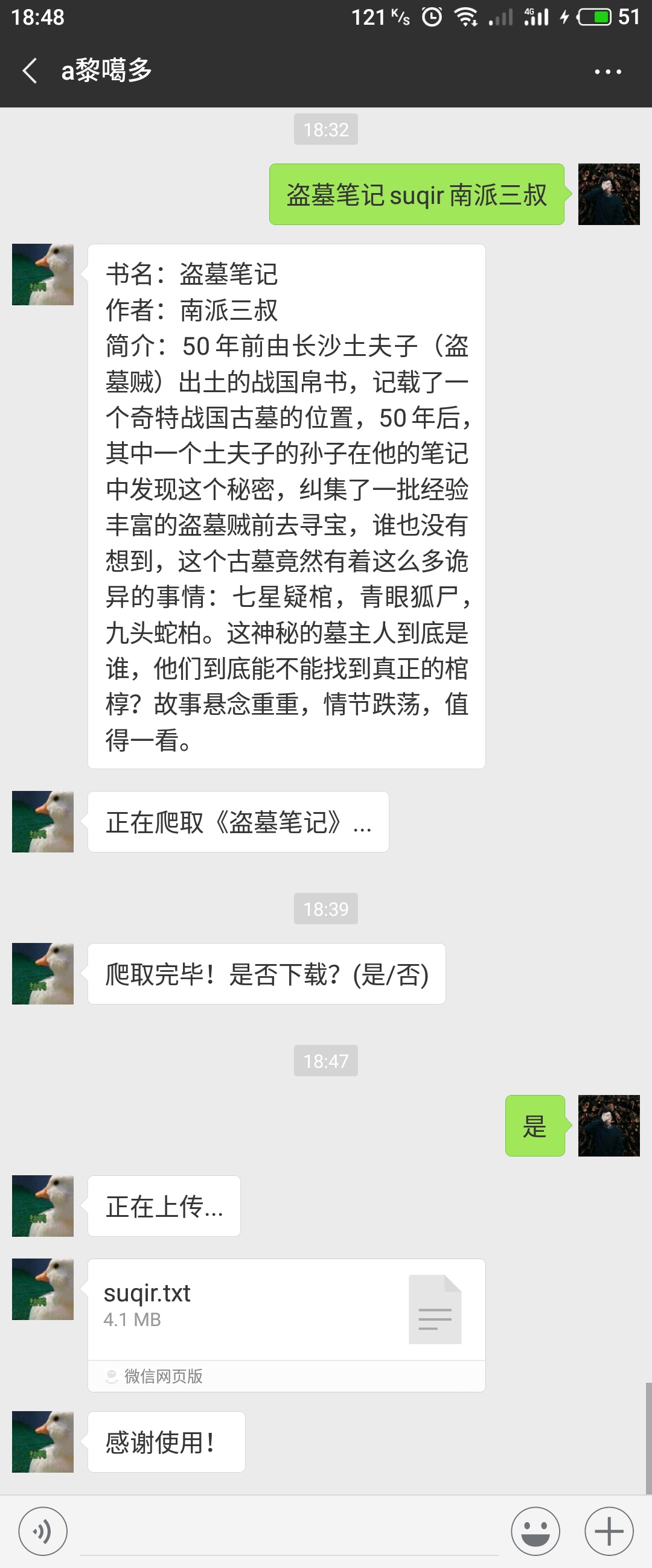
itchat.send('书名:%s\n作者:%s\n简介:%s' % (bookName,bookAuthor,book.get_des()),toUserName=userName)
itchat.send('正在爬取《%s》...' % bookName,toUserName=userName)
print('[*]正在爬取《%s》...' % bookName)
book.save()
itchat.send('爬取完毕!是否下载?(是/否)',toUserName=userName)
except ValueError:
if msg['Text'] == '是':
print('[*]正在发送文件...')
itchat.send('正在上传...',toUserName=userName)
itchat.send_file('./book/suqir.txt',toUserName=userName)
print('[*]已发送文件!\n等待下次请求...')
itchat.send('感谢使用!',toUserName=userName)
elif msg['Text'] == '否':
itchat.send('已取消,感谢使用!',toUserName=userName)
if __name__ == '__main__':
print('[*]Starting...')
userName = getUserName()
itchat.run()
|